关于该代码的大致介绍及其环境配置在代码github仓库已经进行过了,但那是针对有一定视觉经验的人写的代码大致实现思路。
本教程主要针对与缺少视觉经验的新手,在了解代码的同时从中学习到视觉的基本思路和实现方法。虽说是详解,但实际并不可能将代码每个变量的含义都讲解清楚,尤其是OpenCV库内的变量,这部分请自行百度。该详解注重算法实现思路。
前置知识基础:C++
我将从main.cpp开始,按照深度优先顺序对程序进行讲解。同时,我主要讲解代码中的算法部分,其余还有调试代码,辅助代码等,可以自行查看。
本教程较长,建议配合源码食用,注意运行环境的配置,详见代码github仓库。
一、main.cpp
作为主函数,一上来的任务就是进行程序的初始化操作
processOptions(argc, argv); // 处理命令行参数
thread receive(uartReceive, &serial); // 开启串口接收线程
int from_camera = 1; // 根据条件选择视频源
if (!run_with_camera) {
cout << "Input 1 for camera, 0 for video files" << endl;
cin >> from_camera;
}
关于初始化操作,注释写的很清楚,其中命令行参数的处理主要是为了调试,具体实现不做赘述,有兴趣可以查看options.h和options.cpp。串口接收的实现同样不做赘述,其源码位于additions.cpp。
接下来,便是根据给定的视频源,打开对应的视频源,并进行初始化。
// 打开视频源
if (from_camera) {
video = new CameraWrapper(ARMOR_CAMERA_EXPOSURE, ARMOR_CAMERA_GAIN, 2);
} else {
video = new VideoWrapper(PROJECT_DIR"/video/blue_big.avi");
}
if (video->init()) {
LOGM("video_source initialization successfully.");
} else {
LOGW("video_source unavailable!");
}
其中的CameraWrapper类,请参见摄像头部分。
接下来跳过10帧图片,随后进入主循环。在主循环中,由于步兵需要击打能量机关,其实就是一个判断状态,然后根据状态选择运行识别算法。但在代码中可以看见,实际还有很多其他的代码,这些代码主要用于调试,错误处理等功能,包括摄像头断线重连,录制视频,图像显示,状态切换初始化等。同样不做赘述。实际调用算法的函数为
energy.run(src); // 能量机关主函数
armor_finder.run(src); // 自瞄主函数
其中energy为Energy类的对象,armor_finder为ArmorFinder类的对象。
二、摄像头部分
摄像头是做视觉的硬件基础,同时有一个好的摄像头和镜头可以让我们获取一张干净的图片,从而降低图像处理过程中的难度。
camera_wrapper.h和camera_wrapper.cpp两个文件分别定义了摄像头类及其成员函数实现。
我们首先看camera_wrapper.h中的一部分
class CameraWrapper: public WrapperHead
CameraWrapper类继承了WrapperHead类,其中WrapperHead类是一个接口类,目的是为了在主函数中方便的切换视频源(摄像头和视频)。这个类实现了作为一个视频源的基础功能
bool init() final;
bool read(cv::Mat& src) final;
上面两个函数声明是CameraWrapper类的两个public类型的成员函数声明,分别对应了视频源的初始化(初始化成功则返回true否则返回false)和读取一帧图片(读取成功则返回true否则返回false)。
bool init()函数
在init()函数中,主要是使用相机SDK对相机进行初始化,这里不做赘述,主要讲一下几个可能需要根据环境调节的相机参数。
CameraReadParameterFromFile(h_camera, PROJECT_DIR"/others/MV-UB31-Group0.config");
CameraLoadParameter(h_camera, PARAMETER_TEAM_A);
CameraSetExposureTime(h_camera, exposure * 1000);
CameraSetAnalogGain(h_camera, gain);
前两行从相机配置文件中加载了相机参数,该配置文件是由该相机生产公司提供的GUI调参工具自动生成的(主要参数包括,白平衡,伽马值,LUT表等),而后两行分别重新设置了相机的曝光时间和模拟增益,其中exposure和gain是类构造函数时传入的曝光时间和模拟增益。
关于曝光时间,曝光时间越长,图片亮度越高,但更容易出现由于摄像头和目标发生相对移动而产生的模糊现象。
关于模拟增益,模拟增益越高,图片亮度越高,但噪声也越强。
在2019赛季中,由于一直面临亮度不足的问题,所以这两个参数都调整的比较大。
bool read(cv::Mat &src)函数
我们首先看源码
bool CameraWrapper::read(cv::Mat &src) {
if(init_done) {
if (mode == 0)return readProcessed(src);
if (mode == 1)return readRaw(src);
if (mode == 2)return readCallback(src);
} else {
return false;
}
}
只要已经完成初始化,read函数将根据模式选择一个读取方式。由于2019赛季实际采用的读取方式是mode==2`对应的方法,这里主要对其进行讲解。其他读取方式可自行阅读代码。
首先我们讲一下常规程序运行流程,顺序执行
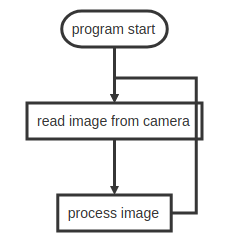
一帧图像的读取经过曝光及数据传输,在2019赛季的配置下需要大约10ms。一张图片的处理,平均需要6ms。这样算下来,整个一帧图像总共需要大约16ms的时间,但其中有10ms的时间cpu处于等待状态,这显然没有充分利用cpu资源。能想到的办法就是当上一帧图像开始处理时,就立马进行下一帧图像的读取,充分利用cpu资源。具体的实现方式略有区别但大致相同。
首先我使用了相机SDK的采集回调函数,并将相机设置为连续采集模式,及相机连续采集图像,每当一帧图像采集完毕时,调用用户注册的回调函数对用户进行通知。
在回调函数中,将采集到的图像保存在该相机对象的一个循环队列之中,关键代码:
c->src_queue.push(cv::cvarrToMat(iplImage).clone());
其中c是相机对象的指针,src_queue是对象中的循环队列。
而此时读取函数只需要判断队列中是否有未读取的图片,如果有就读取否则继续等待即可。
bool CameraWrapper::readCallback(cv::Mat &src) {
systime ts, te;
getsystime(ts);
while(src_queue.empty()){
getsystime(te);
if(getTimeIntervalms(te, ts) > 500){
return false;
}
}
return src_queue.pop(src);
}
采用计时的方式,如果超过500ms没有等到下一帧图片则报错。
此时程序以并行的方式运行,即:
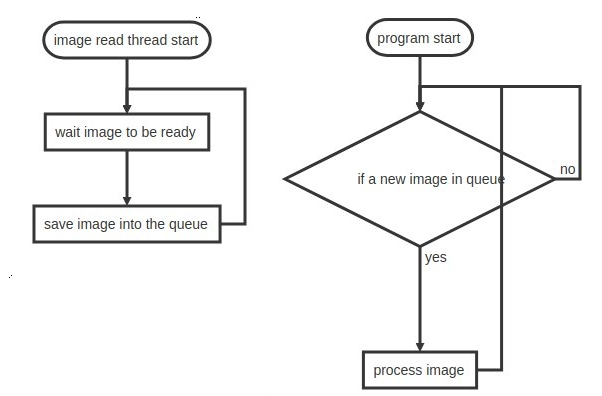
此时,在之前的条件下,一帧图像的总的时间只需要10ms。
三、ArmorFinder类
该类为自瞄算法的封装类,实现了包括装甲版识别,装甲板追踪,陀螺击打,数据发送等功能。对外提供接口void run(cv::Mat &src);主函数只需要调用该成员函数即可完成一帧图像从处理到数据发送的全过程。
1.主要成员变量解析
这部分在armor_finder.h中通过注释写的很清楚,每当在代码中看见记不清干什么的成员变量可以返回该文件查看。
2.void run(cv::Mat &src);函数
该函数维护了一个状态机,这决定这一帧图像使用什么方法进行识别(搜寻或追踪)。
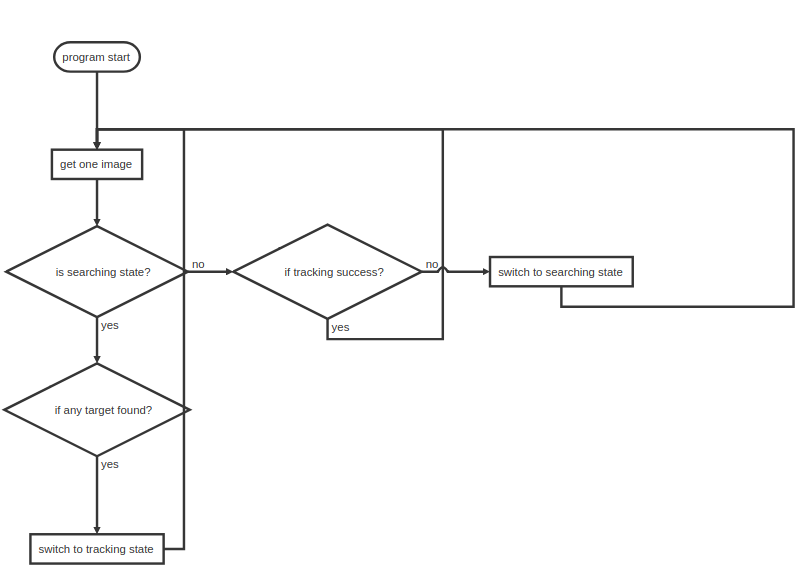
函数首先是一个switch-case结构,完成状态机的功能。
switch (state) {
case SEARCHING_STATE:
// 此处为调用搜寻算法
if (stateSearchingTarget(src)) {
// 判断装甲板区域是否脱离图像区域
if ((target_box.rect & cv::Rect2d(0, 0, 640, 480)) == target_box.rect) {
if (!classifier) {
cv::Mat roi = src(target_box.rect).clone(), roi_gray;
cv::cvtColor(roi, roi_gray, CV_RGB2GRAY);
cv::threshold(roi_gray, roi_gray, 180, 255, cv::THRESH_BINARY);
contour_area = cv::countNonZero(roi_gray);
}
tracker = TrackerToUse::create();
// 成功搜寻到装甲板,创建tracker对象
tracker->init(src, target_box.rect);
state = TRACKING_STATE;
tracking_cnt = 0;
LOGM(STR_CTR(WORD_LIGHT_CYAN, "into track"));
}
}
break;
case TRACKING_STATE:
// 此处为调用追踪算法
if (!stateTrackingTarget(src) || ++tracking_cnt > 100) {
// 最多追踪100帧图像
state = SEARCHING_STATE;
LOGM(STR_CTR(WORD_LIGHT_YELLOW, "into search!"));
}
break;
case STANDBY_STATE:
default:
stateStandBy(); // currently meaningless
}
可以看到这里状态机切换的逻辑为
在switch-case结构执行完毕后,成员变量target_box将存储这一帧图像的目标的结果。如果有目标则保存目标信息,否则为空。在这之后判断是否执行反陀螺代码,以及目标信息的发送。即
if(is_anti_top) { // 判断当前是否为反陀螺模式
antiTop();
}else if(target_box.rect != cv::Rect2d()) {
anti_top_cnt = 0;
time_seq.clear();
angle_seq.clear();
sendBoxPosition(0);
}
其中如果为反陀螺,目标信息在反陀螺函数中进行发送,否则直接发送目标信息。
3.搜寻模式
搜寻模式主函数为bool stateSearchingTarget(cv::Mat &src);是ArmorFinder类的私有成员函数。但其工作则是调用bool findArmorBox(const cv::Mat &src, ArmorBox &box);进行目标搜寻,再进行反目标切换工作。这里findArmorBox才是实际的算法代码。
在findArmorBox函数中,首先对灯条进行寻找,如果找到了,则将所有可能是的灯条的信息保存在局部变量light_blobs中,否则返回false表示搜寻失败。其中light_blobs为LightBlobs类的对象,其定义参见armor_finder.h
if (!findLightBlobs(src, light_blobs)) {
return false;
}
然后对所有灯条进行两两匹配。因为我们的目标——装甲板,有两个灯条,这两个灯条有许多位置和形状特征,我们可以由此匹配出一些可能是装甲板的候选区。如果匹配成功,则将所有装甲板候选区的信息保存在局部变量armor_boxes中,否则返回false表示搜寻失败。其中armor_boxes为ArmorBoxes类的对象,其定义参见armor_finder.h
if (!matchArmorBoxes(src, light_blobs, armor_boxes)) {
return false;
}
在成功获取候选区之后,我们对候选区使用分类器二次筛选,去掉其中不是装甲板的区域,并识别出是装甲板区域的数字编号。其中id==0表示不是装甲板。classifier为Classifier类的对象,是分类器的实体,其定义和实现参见classifier.h和classifier.cpp。
for (auto &armor_box : armor_boxes) {
cv::Mat roi = src(armor_box.rect).clone();
cv::resize(roi, roi, cv::Size(48, 36));
int c = classifier(roi);
armor_box.id = c;
}
由于一帧图像可能有多个目标,所以需要有一个优先级策略来选择一个最优目标。即如果上一帧有目标,则选择离其最近的目标,否则按照装甲板id的优先级进行击打。
// 按照优先级对装甲板进行排序
sort(armor_boxes.begin(), armor_boxes.end(), [&](const ArmorBox &a, const ArmorBox &b) {
if (last_box.rect != cv::Rect2d()) {
return getPointLength(a.getCenter() - last_box.getCenter()) <
getPointLength(b.getCenter() - last_box.getCenter());
} else {
return a < b;
}
});
3.1灯条搜寻
即bool ArmorFinder::findLightBlobs(const cv::Mat &src, LightBlobs &light_blobs)函数。
首先介绍灯条搜寻的思路,利用灯条的亮度和其周围有明显区分度这一条件,我们可以对图像的亮度进行二值化(二值化:一种将图像每个像素点根据特定条件变成非0即1的操作)。找出其中的轮廓(轮廓寻找:所有常规方法进行目标搜寻的关键操作,在二值化后的图像上找出所有联通区域)。最后对所有轮廓利用灯条的形状特征进行筛选,得到可能是灯条的区域。
所以灯条搜寻的第一步是二值化,由于这里利用亮度条件进行灯条的搜寻,所以二值化方法便是将二值化阈值(threshold)一下的设为0,其余设为1。一个好的二值化应该能够使得灯条区域不和其他区域发生联通。这里我采用在目标颜色通道上进行二值化,并且对不同颜色选择不同二值化阈值,同时使用一高一低两个阈值,得到两幅二值图。
cv::split(src, channels); /************************/
if (enemy_color == ENEMY_BLUE) { /* */
color_channel = channels[0]; /* 根据目标颜色进行通道提取 */
} else if (enemy_color == ENEMY_RED) {/* */
color_channel = channels[2]; /************************/
}
int light_threshold;
if(enemy_color == ENEMY_BLUE){
light_threshold = 225;
}else{
light_threshold = 200;
}
// 二值化对应通道
cv::threshold(color_channel, src_bin_light, light_threshold, 255, CV_THRESH_BINARY);
if (src_bin_light.empty()) return false;
imagePreProcess(src_bin_light); // 开闭运算
// 二值化对应通道
cv::threshold(color_channel, src_bin_dim, 140, 255, CV_THRESH_BINARY);
if (src_bin_dim.empty()) return false;
imagePreProcess(src_bin_dim); // 开闭运算
由于二值化极度依赖二值化参数(这里是阈值threshold),所以得到的二值图往往会有一些噪声,所以第二步是使用开闭运算进行处理。开闭运算是什么及其作用请百度。
一二两步之后,我们期待得到了一幅(或两幅)比较完美的二值图,接下来第三步就是轮廓提取。轮廓提取使用的是OpenCV自带的函数findContours,其用法很多,详情请百度。
总之,在light_contours_light, light_contours_dim中保存了轮廓信息,在hierarchy_light, hierarchy_dim中保存了轮廓的层级信息。
std::vector<std::vector<cv::Point>> light_contours_light, light_contours_dim;
std::vector<cv::Vec4i> hierarchy_light, hierarchy_dim;
cv::findContours(src_bin_light, light_contours_light, hierarchy_light, CV_RETR_CCOMP, CV_CHAIN_APPROX_NONE);
cv::findContours(src_bin_dim, light_contours_dim, hierarchy_dim, CV_RETR_CCOMP, CV_CHAIN_APPROX_NONE);
成功获取轮廓之后,第四步就是对轮廓进行筛选,利用的是灯条的形状信息。
for (int i = 0; i < light_contours_light.size(); i++) {
if (hierarchy_light[i][2] == -1) {
cv::RotatedRect rect = cv::minAreaRect(light_contours_light[i]);
if (isValidLightBlob(light_contours_light[i], rect)) {
light_blobs_light.emplace_back(
rect, areaRatio(light_contours_light[i], rect),
get_blob_color(src, rect) //获取灯条颜色
);
}
}
}
通过isValidLightBlob函数判断是否该区域可能是灯条,如果是则添加到light_blobs_light中(PS:这里只展示了两个二值图两个轮廓中的其中一个轮廓的筛选代码,另一个同理)。具体的筛选条件这里不做展示,可以参见find_light_blobs.cpp。可以添加更多已经更加严苛的条件,排除更多不是灯条的区域。但由于二值化得到的二值图往往并不理想,所以该代码中并没有使用较为严苛的筛选条件。
由于使用了一高一低两种二值化阈值进行了两次轮廓提取和筛选,同一个灯条可能同时存在于两个轮廓。这将极大增加后续处理的冗余计算,所以第五步是重复区域的剔除。这部分代码我感觉写的不太好,还有优化空间,这里就不放出来了,可以自行查看。
3.2灯条匹配
灯条匹配同样利用装甲板的形状信息,包括但不限于两个灯条角度,两个灯条的距离,装甲板自身角度。使用二重循环O(n^2)的复杂度进行两两匹配,同样使用
static bool isCoupleLight(const LightBlob &light_blob_i, const LightBlob &light_blob_j, uint8_t enemy_color)
判断两个灯条是否可以匹配,如果可以则保存下来。具体实现不算复杂,可以参见find_armor_box.cpp。
3.3候选区二次筛选
使用分类器进行二次筛选,这里分类器是一个使用TensorFlow训练的小型神经网络。在c++中的前向计算为了方便,利用for循环和Eigen3矩阵库自行编写了一个,没有性能损失。详细可以参见classifier.h和classifier.cpp。
3.4搜寻模式总结
可以看到,目标搜寻就是可以产生候选区和筛选候选区的过程。而主要难点在于候选区的生成。以后其他类似的目标搜寻任务其实也是这样一个思路。常见的候选区生成方式:二值图上轮廓提取。
4.追踪模式
追踪模式,顾名思义就是根据上一帧目标的位置得出这一帧的目标。其好处在于快速,简单。说简单是因为OpenCV有自带的追踪算法。我使用的是其中的KCF追踪算法,关于KCF的原理,比较难,有兴趣自行百度。在OpenCV由KCFTracker类提供目标追踪接口。该算法对象首先需要初始化,即第一次指定目标好开始后续追踪。
tracker->init(src, target_box.rect);
随后在追踪模式主函数bool ArmorFinder::stateTrackingTarget(cv::Mat &src)(函数实现位置:tracking_state.cpp)更新即可。
if(!tracker->update(src, pos)){ // 使用KCFTracker进行追踪
target_box = ArmorBox();
LOGW("Track fail!");
return false;
}
追踪失败,返回false。
既然KCFTracker这么好用,那么追踪模式只需要几行代码就可以完成。但实际并不如此,这其中有两点原因:
- 由于KCF算法是根据上一帧更新下一帧,所以当追踪时间长了,可能会忘记一开始的目标追到其他地方去。
- 同时由于KCFTracker在追踪的时候,只改变追踪框的位置,而不改变长宽。但在后续数据发送时需要长宽信息进行距离的估算。
针对这两个问题,在代码中这样解决:
- 需要使用分类器判断当前是否追踪错误。
- 将追踪区域扩大一倍重新搜寻一次目标,由于搜寻区域小,速度较快。
由于重新搜寻并不总是可以成功,而追踪却往往可以成功。所以,重新搜寻如果失败,还是使用分类器作为当前是否跟丢的判断依据,在后续数据发送时,舍弃小部分距离精准度,换取位置信息的连续性。
ArmorBox box;
// 在区域内重新搜索。
if(findArmorBox(roi, box)) { // 如果成功获取目标,则利用搜索区域重新更新追踪器
target_box = box;
target_box.rect.x += bigger_rect.x; // 添加roi偏移量
target_box.rect.y += bigger_rect.y;
for(auto &blob : target_box.light_blobs){
blob.rect.center.x += bigger_rect.x;
blob.rect.center.y += bigger_rect.y;
}
tracker = TrackerToUse::create();
tracker->init(src, target_box.rect);
}else{ // 如果没有成功搜索目标,则使用判断是否跟丢。
roi = src(pos).clone();
if(classifier){ // 分类器可用,使用分类器判断。
cv::resize(roi, roi, cv::Size(48, 36));
if(classifier(roi) == 0){
target_box = ArmorBox();
LOGW("Track classify fail range!");
return false;
}
}else{ // 分类器不可用,使用常规方法判断(基本弃用)
cv::Mat roi_gray;
cv::cvtColor(roi, roi_gray, CV_RGB2GRAY);
cv::threshold(roi_gray, roi_gray, 180, 255, cv::THRESH_BINARY);
contour_area = cv::countNonZero(roi_gray);
if(abs(cv::countNonZero(roi_gray) - contour_area) > contour_area * 0.3){
target_box = ArmorBox();
return false;
}
}
target_box.rect = pos;
target_box.light_blobs.clear();
}
5.目标位置解算及数据发送
目标位置包括三个信息,相对摄像头光轴yaw轴方向的偏移角度,相对摄像头光轴pitch轴方向的偏移角度,以及离相机的距离。这里我们采用最简单的相似三角形相机模型进行目标位置的解算。事先标定好相机焦距(以像素为单位),就可以得出角度值。
#define FOCUS_PIXAL_8MM (1488)
#define FOCUS_PIXAL_5MM (917)
#define FOCUS_PIXAL FOCUS_PIXAL_5MM
double dx = rect.x + rect.width / 2 - IMAGE_CENTER_X;
double dy = rect.y + rect.height / 2 - IMAGE_CENTER_Y;
double yaw = atan(dx / FOCUS_PIXAL) * 180 / PI;
double pitch = atan(dy / FOCUS_PIXAL) * 180 / PI;
对于距离的测量,说的简单点就是利用进大远小这样一个知识进行距离估算。网络上有很多使用PNP算法进行距离估算,但其实没必要。PNP应用范围比较广,对于目标的不同姿态都可以计算出距离及其姿态。但在当前的应用场景下,有一个先验条件就是敌方装甲板基本垂直于地面,同时所有装甲板高度相同。所以我们同样使用相似三角形模型,计算可以发现距离和装甲板在图像上所占高度的乘积为一个定值。所以我们事先测量好定值的大小,就可以估算距离。
#define DISTANCE_HEIGHT_5MM (10700.0) // 单位: cm*pixel
#define DISTANCE_HEIGHT DISTANCE_HEIGHT_5MM
double dist = DISTANCE_HEIGHT / rect.height;
数据发送使用USB转TTL进行串口数据发送,位置解算和数据发送具体参见send_target.cpp。
6.反陀螺
常规情况下,自瞄发送目标信息到单片机,单片机上会融合陀螺仪信息对敌方的速度和加速度进行估算,从而向预测点发射子弹进行击打。而当敌方为陀螺时,如果也使用这样的方法,云台会来回晃动,相应速度不够,而且由于预测,子弹会击打到车辆以外的位置,没办法造成有效伤害。所以针对陀螺,需要一个专门的击打方式。
基本思路在于估算敌方陀螺的转动角速度,通过这个角速度,计算出预判击打点。
那么如何估算转动角速度呢?发现,想在任何情况下都对转动角速度进行估算是十分困难的,但当敌我双方没有发送相对移动的时候,则可以计算转动角速度。
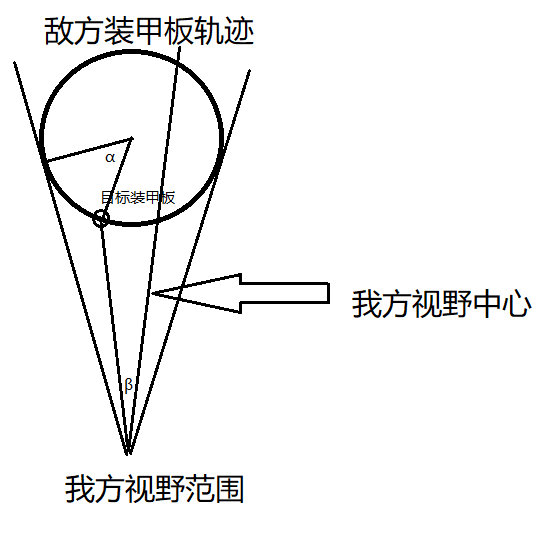
通过简单的几何计算可以发现β∝α,再假设敌方匀速运动,即α∝t,所以β∝t,而β和t都是可以采集到的数据,所以我们可以通过对正面这个装甲板从消失到出现的角度和时间进行线性拟合,得出β=0时对应的时间,这样当我方视野中心正对敌方旋转中心时,连续两次β=0时的时间差,敌方正好转过了90°。从而计算出了转速。
但是由于通常敌方车辆前后装甲板和左右装甲板距离旋转中心的半径不同,当我方视野中心不是正对敌方旋转中心时,连续两次β=0的时间差将不再是90°。如图
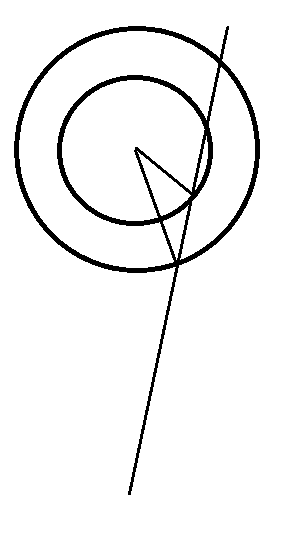
此时我们使用前后装甲板,和左右装甲板分别计算β=0的时间差,这样时间差正好为敌方转过180°的时间。
具体实现参见anti_top.cpp
四、Energy类
能量机关的识别同样采用二值化加轮廓提取获取候选区,利用能量机关的形状特征,对区域进行筛选,最终得到目标,并发送数据。
五、辅助代码介绍
1. log.h
该头文件主要使用宏定义的方式实现了更方便的调试信息输出方式,以及程序运行时间统计。头文件内有较为详细的使用方法介绍。
2. systime.h
该头文件统一了不同平台(Windows,Linux)的系统时间获取接口,是代码跨平台能力更强。